UNIT-5
Explain Directory Structure.
A directory is a container that is used to contain folders and files. It organizes files and folders in a hierarchical manner.

There are several logical structures of a directory, these are given below.
·
Single-level
directory –
The single-level directory is the simplest directory structure. In it, all
files are contained in the same directory which makes it easy to support and
understand.
A single level directory has a significant limitation, however, when the number of files increases or when the system has more than one user. Since all the files are in the same directory, they must have a unique name. if two users call their dataset test, then the unique name rule violated.

Advantages:
· Since it is a single directory, so its implementation is very easy.
· If the files are smaller in size, searching will become faster.
· The operations like file creation, searching, deletion, updating are very easy in such a directory structure.
Disadvantages:
· There may chance of name collision because two files can have the same name.
· Searching will become time taking if the directory is large.
· This can not group the same type of files together.
·
Two-level
directory –
As we have seen, a single level directory often leads to confusion of files
names among different users. the solution to this problem is to create a
separate directory for each user.
In the two-level directory structure, each user has their own user files directory (UFD). The UFDs have similar structures, but each lists only the files of a single user. system’s master file directory (MFD) is searches whenever a new user id=s logged in. The MFD is indexed by username or account number, and each entry points to the UFD for that user.

Advantages:
· We can give full path like /User-name/directory-name/.
· Different users can have the same directory as well as the file name.
· Searching of files becomes easier due to pathname and user-grouping.
Disadvantages:
· A user is not allowed to share files with other users.
·
Still, it not
very scalable, two files of the same type cannot be grouped together in the
same user.
·
Tree-structured
directory –
Once we have seen a two-level directory as a tree of height 2, the natural
generalization is to extend the directory structure to a tree of arbitrary
height.
This generalization allows the user to create their own subdirectories and to
organize their files accordingly.

A tree structure is the most common directory structure. The tree has a root directory, and every file in the system has a unique path.
Advantages:
· Very general, since full pathname can be given.
· Very scalable, the probability of name collision is less.
· Searching becomes very easy, we can use both absolute paths as well as relative.
Disadvantages:
· Every file does not fit into the hierarchical model, files may be saved into multiple directories.
· We can not share files.
2. Explain File Operations in Os.
Operations on the File
A file is a collection of logically related data that is recorded on the secondary storage in the form of sequence of operations. The content of the files are defined by its creator who is creating the file. The various operations which can be implemented on a file such as read, write, open and close etc. are called file operations.
1.Create operation:
This operation is used to create a file in the file system. It is the most widely used operation performed on the file system. To create a new file of a particular type the associated application program calls the file system. This file system allocates space to the file. As the file system knows the format of directory structure, so entry of this new file is made into the appropriate directory.
2. Open operation:
This operation is the common operation performed on the file. Once the file is created, it must be opened before performing the file processing operations. When the user wants to open a file, it provides a file name to open the particular file in the file system. It tells the operating system to invoke the open system call and passes the file name to the file system.
3. Write operation:
This operation is used to write the information into a file. A system call write is issued that specifies the name of the file and the length of the data has to be written to the file. Whenever the file length is increased by specified value and the file pointer is repositioned after the last byte written.
4. Read operation:
This operation reads the contents from a file. A Read pointer is maintained by the OS, pointing to the position up to which the data has been read.
5. Re-position or Seek operation:
The seek system call re-positions the file pointers from the current position to a specific place in the file i.e. forward or backward depending upon the user's requirement. This operation is generally performed with those file management systems that support direct access files.
6. Delete operation:
Deleting the file will not only delete all the data stored inside the file it is also used so that disk space occupied by it is freed. In order to delete the specified file the directory is searched. When the directory entry is located, all the associated file space and the directory entry is released.
7. Truncate operation:
Truncating is simply deleting the file except deleting attributes. The file is not completely deleted although the information stored inside the file gets replaced.
8. Close operation:
When the processing of the file is complete, it should be closed so that all the changes made permanent and all the resources occupied should be released. On closing it deallocates all the internal descriptors that were created when the file was opened.
3. Explain File Allocation Methods.
File Allocation Methods
The allocation methods define how the files are stored in the disk blocks. There are three main disk space or file allocation methods.
· Contiguous Allocation
· Linked Allocation
· Indexed Allocation
The main idea behind these methods is to provide:
· Efficient disk space utilization.
· Fast access to the file blocks.
All the three methods have their own advantages and disadvantages as discussed below:
1. Contiguous Allocation
In this scheme, each file occupies a contiguous set of
blocks on the disk. For example, if a file requires n blocks and is given a
block b as the starting location, then the blocks assigned to the file will be: b, b+1, b+2,……b+n-1. This
means that given the starting block address and the length of the file (in
terms of blocks required), we can determine the blocks occupied by the file.
The directory entry for a file with contiguous allocation contains
· Address of starting block
· Length of the allocated portion.
The file ‘mail’ in the following figure starts from the block 19 with length = 6 blocks. Therefore, it occupies 19, 20, 21, 22, 23, 24 blocks.
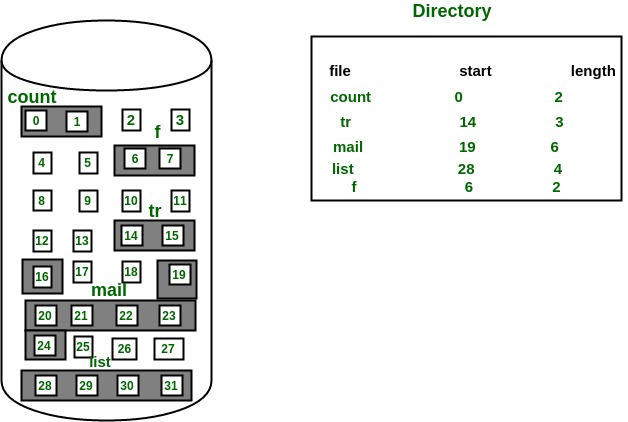
Advantages:
· Both the Sequential and Direct Accesses are supported by this. For direct access, the address of the kth block of the file which starts at block b can easily be obtained as (b+k).
· This is extremely fast since the number of seeks are minimal because of contiguous allocation of file blocks.
Disadvantages:
· This method suffers from both internal and external fragmentation. This makes it inefficient in terms of memory utilization.
· Increasing file size is difficult because it depends on the availability of contiguous memory at a particular instance.
2. Linked List Allocation
In this scheme, each file is a linked list of disk blocks
which need not be contiguous.
The disk blocks can be scattered anywhere on the disk.
The directory entry contains a pointer to the starting and the ending file
block. Each block contains a pointer to the next block occupied by the file.
The file ‘jeep’ in following image shows how the blocks are
randomly distributed. The last block (25) contains -1 indicating a null pointer
and does not point to any other block.
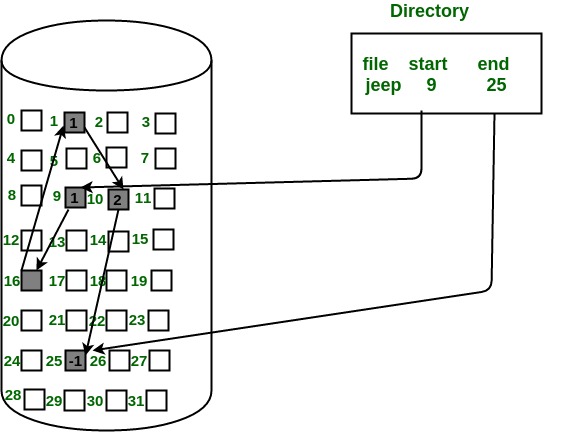
Advantages:
· This is very flexible in terms of file size. File size can be increased easily since the system does not have to look for a contiguous chunk of memory.
· This method does not suffer from external fragmentation. This makes it relatively better in terms of memory utilization.
Disadvantages:
· Because the file blocks are distributed randomly on the disk, a large number of seeks are needed to access every block individually. This makes linked allocation slower.
· It does not support random or direct access. We can not directly access the blocks of a file. A block k of a file can be accessed by traversing k blocks sequentially (sequential access ) from the starting block of the file via block pointers.
· Pointers required in the linked allocation incur some extra overhead.
3. Indexed Allocation
In this scheme, a special block known as the Index block contains the pointers to all the blocks occupied by a file. Each file has its own index block. The ith entry in the index block contains the disk address of the ith file block. The directory entry contains the address of the index block as shown in the image:
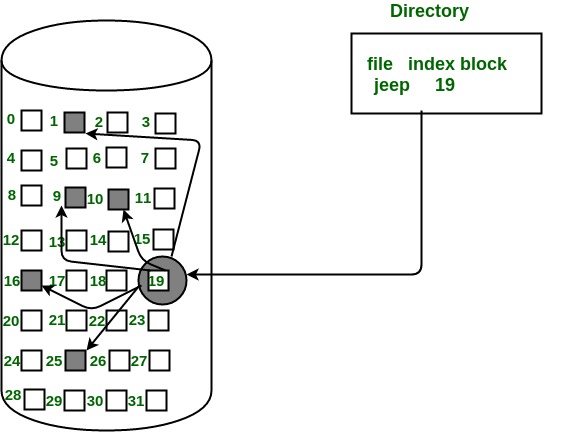
Advantages:
· This supports direct access to the blocks occupied by the file and therefore provides fast access to the file blocks.
· It overcomes the problem of external fragmentation.
Disadvantages:
· The pointer overhead for indexed allocation is greater than linked allocation.
· For very small files, say files that expand only 2-3 blocks, the indexed allocation would keep one entire block (index block) for the pointers which is inefficient in terms of memory utilization. However, in linked allocation we lose the space of only 1 pointer per block.
Explain Device Management in Operating System.
Device Management in Operating System
Device management in an operating system means controlling the Input/Output devices like disk, microphone, keyboard, printer, magnetic tape, USB ports, camcorder, scanner, other accessories, and supporting units like supporting units control channels. A process may require various resources, including main memory, file access, and access to disk drives, and others. If resources are available, they could be allocated, and control returned to the CPU.
The fundamentals of I/O devices may be divided into three categories:
- Boot Device
- Character Device
- Network Device
Boot Device
It stores data in fixed-size blocks, each with its unique address. For example- Disks.
Character Device
It transmits or accepts a stream of characters, none of which can be addressed individually. For instance, keyboards, printers, etc.
Network Device
It is used for transmitting the data packets.
Functions of the device management in the operating system
The operating system (OS) handles communication with the devices via their drivers. The OS component gives a uniform interface for accessing devices with various physical features. There are various functions of device management in the operating system. Some of them are as follows:
- It keeps track of data, status, location, uses, etc. The file system is a term used to define a group of facilities.
- It enforces the pre-determined policies and decides which process receives the device when and for how long.
- It improves the performance of specific devices.
- It monitors the status of every device, including printers, storage drivers, and other devices.
- It allocates and effectively deallocates the device. De-allocating differentiates the devices at two levels: first, when an I/O command is issued and temporarily freed. Second, when the job is completed, and the device is permanently release
Types of devices
There are three types of Operating system peripheral devices: dedicated, shared, and virtual. These are as follows:
1. Dedicated Device
In device management, some devices are allocated or assigned to only one task at a time until that job releases them. Devices such as plotters, printers, tape drivers, and other similar devices necessitate such an allocation mechanism because it will be inconvenient if multiple people share them simultaneously. The disadvantage of such devices is the inefficiency caused by allocating the device to a single user for the whole duration of task execution, even if the device is not used 100% of the time.
2. Shared Devices
These devices could be assigned to a variety of processes. By interleaving their requests, disk-DASD could be shared by multiple processes simultaneously. The Device Manager carefully controls the interleaving, and pre-determined policies must resolve all difficulties.
3. Virtual Devices
Virtual devices are a hybrid of the two devices, and they are dedicated devices that have been transformed into shared devices. For example, a printer can be transformed into a shareable device by using a spooling program that redirects all print requests to a disk. A print job is not sent directly to the printer; however, it is routed to the disk until it is fully prepared with all of the required sequences and formatting, at which point it is transmitted to the printers. The approach can transform a single printer into numerous virtual printers, improving performance and ease of use.
4.Write about Pipes in operating System.
Conceptually, a pipe is a connection between two processes, such that the standard output from one process becomes the standard input of the other process. In UNIX Operating System, Pipes are useful for communication between related processes(inter-process communication).
· Pipe is one-way communication only i.e we can use a pipe such that One process write to the pipe, and the other process reads from the pipe. It opens a pipe, which is an area of main memory that is treated as a “virtual file”.
· The pipe can be used by the creating process, as well as all its child processes, for reading and writing. One process can write to this “virtual file” or pipe and another related process can read from it.
· If a process tries to read before something is written to the pipe, the process is suspended until something is written.
· The pipe system call finds the first two available positions in the process’s open file table and allocates them for the read and write ends of the pipe.

Parent and child sharing a pipe
When we use fork in any process, file descriptors remain open across child process and also parent process. If we call fork after creating a pipe, then the parent and child can communicate via the pipe.
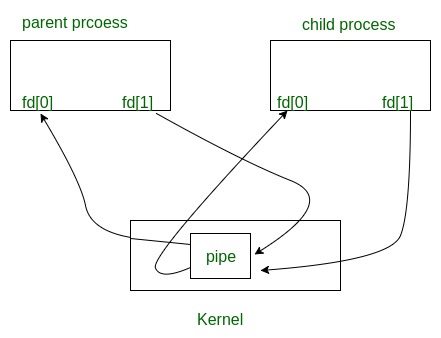
Write about Buffer in OS.
· The buffer is an area in the main memory used to store or hold the data temporarily. In other words, buffer temporarily stores data transmitted from one place to another, either between two devices or an application. The act of storing data temporarily in the buffer is called buffering.
· A buffer may be used when moving data between processes within a computer. Buffers can be implemented in a fixed memory location in hardware or by using a virtual data buffer in software, pointing at a location in the physical memory. In all cases, the data in a data buffer are stored on a physical storage medium.
Types of Buffering
There are three main types of buffering in the operating system, such as:

1. Single Buffer
In Single Buffering, only one buffer is used to transfer the data between two devices. The producer produces one block of data into the buffer. After that, the consumer consumes the buffer. Only when the buffer is empty, the processor again produces the data.

Block oriented device: The following operations are performed in the block-oriented device,
- System buffer takes the input.
- After taking the input, the block gets transferred to the user space and then requests another block.
- Two blocks work simultaneously. When the user processes one block of data, the next block is being read in.
- OS can swap the processes.
- OS can record the data of the system buffer to user processes.
Stream oriented device: It performed the following operations, such as:
- Line-at a time operation is used for scroll made terminals. The user inputs one line at a time, with a carriage return waving at the end of a line.
- Byte-at a time operation is used on forms mode, terminals when each keystroke is significant.
2. Double Buffer
In Double Buffering, two schemes or two buffers are used in the place of one. In this buffering, the producer produces one buffer while the consumer consumes another buffer simultaneously. So, the producer not needs to wait for filling the buffer. Double buffering is also known as buffer swapping.

Block oriented: This is how a double buffer works. There are two buffers in the system.
- The driver or controller uses one buffer to store data while waiting for it to be taken by a higher hierarchy level.
- Another buffer is used to store data from the lower-level module.
- A major disadvantage of double buffering is that the complexity of the process gets increased.
- If the process performs rapid bursts of I/O, then using double buffering may be deficient.
Stream oriented: It performs these operations, such as:
- Line- at a time I/O, the user process does not need to be suspended for input or output unless the process runs ahead of the double buffer.
- Byte- at time operations, double buffer offers no advantage over a single buffer of twice the length.
3. Circular Buffer
When more than two buffers are used, the buffers' collection is called a circular buffer. Each buffer is being one unit in the circular buffer. The data transfer rate will increase using the circular buffer rather than the double buffering.

- In this, the data do not directly pass from the producer to the consumer because the data would change due to overwriting of buffers before consumed.
- The producer can only fill up to buffer x-1 while data in buffer x is waiting to be consumed.
Explain Shared Memory in Operating System.
· Shared memory is a memory shared between two or more processes.
· To reiterate, each process has its own address space, if any process wants to communicate with some information from its own address space to other processes, then it is only possible with IPC (inter process communication) techniques. As we are already aware, communication can be between related or unrelated processes.
the IPC techniques of Pipes and Named pipes and now it is time to know the remaining IPC techniques viz., Shared Memory, Message Queues, Semaphores, Signals, and Memory Mapping.
In this chapter, we will know all about shared memory.

We know that to communicate between two or more processes, we use shared memory but before using the shared memory what needs to be done with the system calls, let us see this −
· Create the shared memory segment or use an already created shared memory segment (shmget())
· Attach the process to the already created shared memory segment (shmat())
· Detach the process from the already attached shared memory segment (shmdt())
· Control operations on the shared memory segment (shmctl())
· Let us look at a few details of the system calls related to shared memory.
· #include <sys/ipc.h>
· #include <sys/shm.h>
·
· int shmget(key_t key, size_t size, int shmflg)
· The above system call creates or allocates a System V shared memory segment. The arguments that need to be passed are as follows −
· The first argument, key, recognizes the shared memory segment. The key can be either an arbitrary value or one that can be derived from the library function ftok(). The key can also be IPC_PRIVATE, means, running processes as server and client (parent and child relationship) i.e., inter-related process communiation. If the client wants to use shared memory with this key, then it must be a child process of the server. Also, the child process needs to be created after the parent has obtained a shared memory.
· The second argument, size, is the size of the shared memory segment rounded to multiple of PAGE_SIZE.
· The third argument, shmflg, specifies the required shared memory flag/s such as IPC_CREAT (creating new segment) or IPC_EXCL (Used with IPC_CREAT to create new segment and the call fails, if the segment already exists). Need to pass the permissions as well.
Explain about Security policy Mechanism.
Operating System Security Policies and Procedures
Various operating system security policies may be implemented based on the organization that you are working in. In general, an OS security policy is a document that specifies the procedures for ensuring that the operating system maintains a specific level of integrity, confidentiality, and availability.
OS Security protects systems and data from worms, malware, threats, ransomware, backdoor intrusions, viruses, etc. Security policies handle all preventative activities and procedures to ensure an operating system's protection, including steal, edited, and deleted data.
As OS security policies and procedures cover a large area, there are various techniques to addressing them. Some of them are as follows:
- Installing and updating anti-virus software
- Ensure the systems are patched or updated regularly
- Implementing user management policies to protect user accounts and privileges.
- Installing a firewall and ensuring that it is properly set to monitor all incoming and outgoing traffic.
OS security policies and procedures are developed and implemented to ensure that you must first determine which assets, systems, hardware, and date are the most vital to your organization. Once that is completed, a policy can be developed to secure and safeguard them properly.
Write about protection in os.
Protection and Security Methods
The different methods that may provide protect and security for different computer systems are −
Authentication
This deals with identifying each user in the system and making sure they are who they claim to be. The operating system makes sure that all the users are authenticated before they access the system. The different ways to make sure that the users are authentic are:
- Username/ Password
Each user has a distinct username and password combination and they need to enter it correctly before they can access the system.
- User Key/ User Card
The users need to punch a card into the card slot or use they individual key on a keypad to access the system.
- User Attribute Identification
Different user attribute identifications that can be used are fingerprint, eye retina etc. These are unique for each user and are compared with the existing samples in the database. The user can only access the system if there is a match.
One Time Password
These passwords provide a lot of security for authentication purposes. A one time password can be generated exclusively for a login every time a user wants to enter the system. It cannot be used more than once. The various ways a one time password can be implemented are −
- Random Numbers
The system can ask for numbers that correspond to alphabets that are pre arranged. This combination can be changed each time a login is required.
- Secret Key
A hardware device can create a secret key related to the user id for login. This key can change each time.
Write about Authentication and internal Access Authorization.
· Authorization is the process of giving someone permission to do or have something. In multi-user computer systems, a system administrator defines for the system which users are allowed access to the system and what privileges of use (such as access to which file directories, hours of access, amount of allocated storage space, and so forth).
· Authorization is a process by which a server determines if the client has permission to use a resource or access a file.
· Authorization is usually coupled with authentication so that the server has some concept of who the client is that is requesting access.
· The type of authentication required for authorization may vary; passwords may be required in some cases but not in others.
· In some cases, there is no authorization; any user may be use a resource or access a file simply by asking for it. Most of the web pages on the Internet require no authentication or authorization.
Authentication mechanism determines the users identity before revealing the sensitive information.
Use of Authentication in OS
- Authentication is used by a server when the server needs to know exactly who is accessing their information or site.
- Authentication is used by a client when the client needs to know that the server is system it claims to be.
- In authentication, the user or computer has to prove its identity to the server or client.
- Usually, authentication by a server entails the use of a user name and password. Other ways to authenticate can be through cards, retina scans, voice recognition, and fingerprints.
- Authentication by a client usually involves the server giving a certificate to the client in which a trusted third party such as Verisign or Thawte states that the server belongs to the entity (such as a bank) that the client expects it to.
- Authentication does not determine what tasks the individual can do or what files the individual can see. Authentication merely identifies and verifies who the person or system is.
Operating Systems generally identifies/authenticates users using following three ways
- Username / Password: User need to enter a registered username and password with Operating system to login into the system.
- User card/key: User need to punch card in card slot, or enter key generated by key generator in option provided by operating system to login into the system.
- User attribute - fingerprint/ eye retina pattern/ signature: User need to pass his/her attribute via designated input device used by operating system to login into the system

Comments
Post a Comment